Learn about various types of diagnostic tests and what makes each unique.
Diagnostic tests are invasive or non-invasive tests used for detecting diseases or monitoring their progression. The article below details how to decide which type of diagnostic test is best for certain situations. Clinical epidemiology is a field that uses the data from these diagnostic tests to better understand specific diseases and how they spread.
🔬 Related: Research Support for Life Science Start Ups in Orange County
There are many types of diagnostics tests:
These methods can all be applied to a different disease or problem they are looking for. For example, infectious diseases like COVID-19 can be found by either identifying the virus in biological fluids, or identifying the antibodies after the fact. Physical exams can be used for identifying swelling or redness that may not be apparent in other tests. Because of this variety of symptoms, different tests are needed to diagnose the variety of diseases or problems they could indicate.
In order to better understand clinical epidemiology, you also need to understand a few key concepts relating to test accuracy. One is test sensitivity (Se) and the other is test specificity (Sp). Sensitivity is the proportion of infected individuals that are correctly classified as infected/affected. Specificity is the proportion of the non-affected population that is correctly classified as not infected/affected.
Another concept to understand is the difference between clinical epidemiological terminology and analytical terminology. Analytical terminology states that sensitivity is the smallest detectable unit of change (whether that is a chemical, physiological, etc). Analytical specificity is the potential for misclassification of cross reactivity.
Despite the similar names, the concepts are very different. For the purpose of this article (and clinical epidemiology in general), we will be using the first set of definitions for sensitivity and specificity unless otherwise stated.
There are two main forms of test results: dichotomous and quantitative. Dichotomous means that there are only two outcomes. A common example of this is a positive or a negative test result. Dichotomous tests are often found in clinics and can provide quick results.
Quantitative tests are a series of numbers that then need to be interpreted. These can be percentages, amounts, etc. These are more complicated and often need a lab to perform.
The main issue with quantitative tests is that the results need to be interpreted by a doctor or qualified professional. There is rarely a simple yes or no. Oftentimes there is a cutoff number or amount to distinguish a positive and negative diagnosis. Cut offs can be somewhat arbitrary as well. This may not be satisfying, but the main idea is to establish what should be valued and prioritized in the test.
An example of a common cutoff is a normal distribution curve. This curve looks like a bell shape, and 95% of people are in the middle zone. Using that logic, 2.5% of people will be above and 2.5% of people will be below the cutoff for that particular curve.
Cutoffs need to be considered for non-normal distributions as well. Deciding the cutoff is usually based on past experience and population/sample statistics.
The reality is with a quantitative test, there will always be tradeoffs between test sensitivity and specificity. There are a number of ways to deal with this tradeoff and to document it. You can deal with this tradeoff by creating receiver operating curves (ROCs). ROCs document the false positive rate versus the true positive rate on a graph. If the line is a straight positive correlation, that essentially means that there is a 50% chance of the test being accurate. Please see the graph below to better visualize ROCs.
This curve is a great way to visualize the true positives and to understand how the data can best be used. This type of graph (with individual and specific data) can also be used to perform calculations on the data like integrals, etc. For the above graph, a cutoff on the green line would be ideal at around 1.5 on the x-axis, but some scenarios will require different cutoffs. That is where the ratio starts to level out.
Sadly, in the real world, there are various complications that can affect the results of a quantitative test. One example is the way sensitivity rates are affected by the stage of infection or the immune status of the individual. For example, a false negative could occur with a coronavirus test if you were infected around 1 hour before you take the test. This will make the sensitivity worse as that individual was technically infected, but it will not count them as so.
Specificity can be affected by vaccination and cross-reacting agents. If an individual is vaccinated, it can sometimes be hard to tell whether a detection of the virus in their body is truly an infection or just from the vaccine.
🔬 Read: Vaccine Development and Manufacturing
The best scenario for testing is to have a gold standard to compare results to. Sadly a gold standard is not attainable for many diseases. In its absence, there are mathematical models and testing that can be used to ensure that a test result is valid.
Another important consideration is sampling. Sample size and where the sample comes from will affect the test results, as certain regions could have different responses than others. Valid tests also need to be repeatable and reproducible. Repeatable means that if you were to repeat the test the next day or the next week if they would be comparable. The results need to be comparable between labs in order to be reproducible.
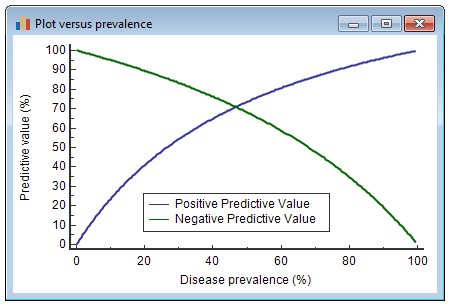
You also need to take into account two things called PPV and NPV. PPV is predicted positive value and NPV is negative predictive value. These represent how confident you are that a positive/negative result is truly positive/negative. Check out the graph below to see a representation of PPV and NPV.
All of these values will also depend on the population prevalence. Population prevalence is if at a given state and time, how many individuals are truly infected. Testing for issues like anthrax versus influenza will be extremely different because the population prevalence is so different. Anthrax is generally uncommon today, while the flu is one of the most common viruses in the US, so false positives and negatives will have different probabilities for each.
The impact on false positives and false negatives will also have a huge impact on the patient and the surrounding area. A false positive for anthrax will be much more intense for a person than a false positive for influenza. Understanding the PPV and NPV for certain tests is essential for relating it to the impact it may have on patients.
The cost of tests are another factor to consider when creating diagnostic tests. Some diseases, like birth defects or genetic diseases will require tests that are more expensive. Because these will be relatively rare to run, the higher cost can be justified. In contrast, diagnostic tests for influenza need to be relatively cheap because they are distributed to a large population.
Increasing the number of tests to diagnose a specific disease is a great way to make diagnosis more accurate. In order for this to be as accurate as possible, the two (or more) tests need to be independent. However, this is easier said than done, as many bodily functions are interconnected. This means that the tests may only be conditionally independent. For example, there can be two antibody tests for different parts of a particular virus. Although they are different parts, there is still some overlap of where they came from (the same virus), so the two tests can not be completely independent. That is acceptable.
Another way to ensure accuracy is to test in series. For example, if one test comes back positive, there can be another test administered. If that one is positive as well, there is a very high chance that the result is accurate. This will increase the specificity of the diagnostic. If you get two positives, you will be increasing the likelihood that that person or animal is actually positive.
Most diagnostic tests are going to be quantitative, and therefore subjective. It is important to understand how the evidence and tradeoffs need to balance that subjectivity. The best is to take each specific situation individually, as each disease or problem needs a different test (or combination of tests).
This information comes from a talk with Dave Miller, ScienceDocs consultant, in partnership with University Lab Partners. Watch the full webinar here.
Dr. Miller is a veterinarian with a PhD in Clinical Science. His PhD studies emphasized the epidemiology of agent transmission, diagnostic testing, and One Health. He has advanced clinical specializations in animal welfare (Diplomate of the American College of Animal Welfare) and zoological medicine (Diplomate of the American College of Zoological Medicine), as well as experience in a variety of laboratory, research, regulatory, exhibition, and other clinical settings.
If you want to learn about business planning, check out this article from ULP about Creating an Effective Business Continuity Plan.
Be sure to subscribe to the ULP Youtube Channel to never miss another webinar, and connect with us on LinkedIn to stay in the loop!
Do you have a great company in the bioscience or medtech industry? Do you need wet-lab and/or fabrication space to develop and test your product?